EN
MySQL - count duplicated rows
0
points
In this article, we would like to show you how to count duplicated rows in MySQL.
Quick solution:
SELECT
`column_name`, COUNT(`column_name`)
FROM
`table_name`
GROUP BY
`column_name`
HAVING
(COUNT(`column_name`) > 1);
Practical example
To show how to count duplicated rows, we will use the following users table:
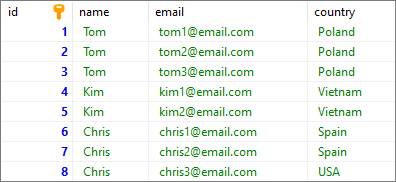
Note:
At the end of this article you can find database preparation SQL queries.
Example
In this example, we will count duplicated user names.
Query:
SELECT
`name`, COUNT(`name`) AS 'count'
FROM
`users`
GROUP BY
`name`
HAVING
(COUNT(`name`) > 1);
Result:
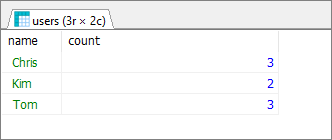
Database preparation
create_tables.sql file:
CREATE TABLE `users` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`email` VARCHAR(100) NOT NULL,
`country` VARCHAR(15) NOT NULL,
PRIMARY KEY (`id`)
)
ENGINE=InnoDB;
insert_data.sql file:
INSERT INTO `users`
(`name`, `email`, `country`)
VALUES
('Tom', 'tom1@email.com', 'Poland'),
('Tom', 'tom2@email.com', 'Poland'),
('Tom', 'tom3@email.com', 'Poland'),
('Kim', 'kim1@email.com', 'Vietnam'),
('Kim', 'kim2@email.com', 'Vietnam'),
('Chris', 'chris1@email.com', 'Spain'),
('Chris', 'chris2@email.com', 'Spain'),
('Chris', 'chris3@email.com', 'USA');