EN
PostgreSQL - GROUP BY multiple columns
0 points
In this article, we would like to show you how to use GROUP BY statement with multiple columns in PostgreSQL.
Quick solution:
xxxxxxxxxx1
SELECT "column1", "column2", "columnN"2
FROM "table_name"3
WHERE condition4
GROUP BY "column1", "column2", "columnN"5
ORDER BY "column_name";To show how GROUP BY with multiple columns works, we will use the following table:
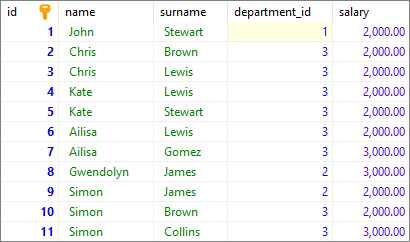
Note:
At the end of this article you can find database preparation SQL queries.
In this example, we will display the number of users with the same name and department_id.
Query:
xxxxxxxxxx1
SELECT "name", "department_id", COUNT(*)2
FROM "users"3
GROUP BY "name","department_id";Result:
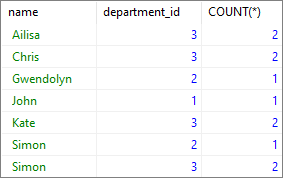
Result explanation:
As we see, the COUNT(*) column contains the number of users with the same name and department_id. For example, there are three people named Ailisa in the department 3.
create_tables.sql file:
xxxxxxxxxx1
CREATE TABLE "users" (2
"id" SERIAL,3
"name" VARCHAR(50) NOT NULL,4
"surname" VARCHAR(50) NOT NULL,5
"department_id" INTEGER,6
"salary" DECIMAL(15,2) NOT NULL,7
PRIMARY KEY ("id")8
);insert_data.sql file:
xxxxxxxxxx1
INSERT INTO "users"2
( "name", "surname", "department_id", "salary")3
VALUES4
('John', 'Stewart', 1, '2000.00'),5
('Chris', 'Brown', 3, '2000.00'),6
('Chris', 'Lewis', 3, '2000.00'),7
('Kate', 'Lewis', 3, '2000.00'),8
('Kate', 'Stewart', 3, '2000.00'),9
('Ailisa', 'Lewis', 3, '2000.00'),10
('Ailisa', 'Gomez', 3, '3000.00'),11
('Gwendolyn', 'James', 2, '3000.00'),12
('Simon', 'James', 2, '2000.00'),13
('Simon', 'Brown', 3, '2000.00'),14
('Simon', 'Collins', 3, '3000.00');
